KI-generierte Texte sind 2026 überall: in Blogartikeln, Bewerbungen, Hausarbeiten und Marketingmaterialien. Parallel dazu ist eine ganze Industrie an Tools entstanden, die versprechen, genau diese Texte zu erkennen. KI-Scanner, KI-Detektoren, AI Content Checker. Die Namen variieren, das Versprechen ist dasselbe: Erkennen, ob ein Text von ChatGPT, Claude oder Gemini geschrieben wurde.
Zusammenfassung:
- KI-Scanner arbeiten mit statistischen Mustern wie Perplexity und Burstiness, ergänzt durch trainierte neuronale Netze.
- Die besten Detektoren erreichen eine Genauigkeit von 70 bis 80 Prozent. Jeder dritte Text wird falsch eingestuft.
- Für deutsche Texte ist die Erkennungsgenauigkeit noch deutlich niedriger.
- Nicht-Muttersprachler werden systematisch häufiger als KI eingestuft.
- Die richtige Frage für Unternehmen lautet nicht "Von wem stammt dieser Text?" sondern "Ist er gut?"
Wie KI-Scanner technisch funktionieren
KI-Scanner versuchen, statistische Muster zu erkennen, die KI-generierte Texte von menschlichen Texten unterscheiden.
Dahinter stecken vor allem zwei Kennzahlen: Perplexity und Burstiness. Perplexity misst, wie vorhersehbar ein Text ist. Wenn ein Sprachmodell den nächsten Satz fast erraten kann, ist die Perplexity niedrig, ein typisches Merkmal für KI-Texte, weil LLMs genau die wahrscheinlichsten Wörter wählen. Burstiness beschreibt, wie stark Satzlänge und Komplexität innerhalb eines Textes variieren. Menschen schreiben ungleichmäßig, mal ein kurzer Satz, dann ein langer Schachtelsatz. KI-Texte halten dagegen ein auffällig gleichmäßiges Niveau.
Moderne Detektoren wie GPTZero, Originality.ai oder Copyleaks gehen über diese beiden Metriken hinaus. Sie nutzen eigene neuronale Netze, die mit großen Mengen an menschlichen und KI-generierten Texten trainiert wurden und Muster erkennen, die für das menschliche Auge unsichtbar sind. Die besten Scanner kombinieren beide Ansätze: statistische Analyse und modellbasierte Klassifikation.
Welche Muster KI-Detektoren erkennen
KI-Texte haben eine Art Handschrift, aber sie ist weniger eindeutig, als viele denken.
Typische Merkmale, auf die Scanner reagieren: gleichmäßige Satzlängen mit wenig Rhythmusvariation, übermäßig höfliche oder formale Sprache, bestimmte Formulierungsmuster wie Dreiergruppen und parallele Satzstrukturen sowie fehlende persönliche Perspektive. KI-Texte wirken oft wie sauber geschriebene Wikipedia-Einträge: korrekt, aber ohne eigene Haltung.
Im Englischen sind diese Muster besonders deutlich. Wörter wie "delve", "tapestry" oder "underscores" gelten mittlerweile als KI-Marker. Im Deutschen ist die Erkennungslage schwieriger. Sprachmodelle produzieren hier weniger offensichtliche Auffälligkeiten, und die Trainingsgrundlage der Scanner ist für deutschsprachige Texte deutlich kleiner.
Wer wissen möchte, welche stilistischen Muster im Deutschen konkret auf KI-Texte hindeuten, findet eine ausführliche Übersicht in unserem Artikel zu den typischen Erkennungsmerkmalen von KI-Texten.
Wie zuverlässig sind KI-Scanner wirklich?
Die ehrliche Antwort: nicht zuverlässig genug, um Entscheidungen darauf zu stützen.
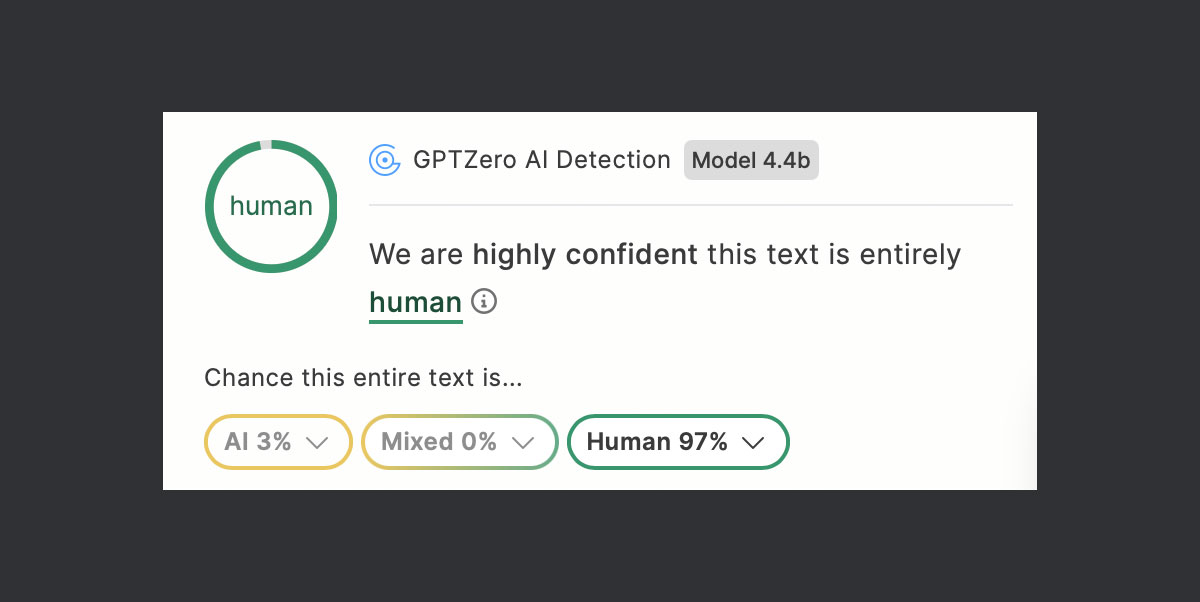
Studien wie von Weber-Wulff et al. (2023) und Arslan (2026) zeigen, dass die besten Scanner eine Genauigkeit von etwa 70 bis 80 Prozent erreichen. Das klingt ordentlich, bedeutet aber: Jeder dritte bis vierte Text wird falsch eingestuft. Besonders problematisch sind sogenannte False Positives, also menschliche Texte, die fälschlicherweise als KI-generiert markiert werden. Die Goethe-Universität Frankfurt hat deshalb festgelegt, dass KI-Detektionsergebnisse nur unterstützend eingesetzt werden dürfen und allein nicht als Nachweis gelten.
Für deutsche Texte ist die Genauigkeit noch deutlich niedriger. Die meisten Scanner wurden primär für englische Texte trainiert. Deutsche Sprachmodelle und die komplexere Grammatik führen zu mehr Fehlurteilen. Pangram Labs hat außerdem gezeigt, dass Texte von Nicht-Muttersprachlern systematisch häufiger als KI eingestuft werden. Ein ernsthaftes Bias-Problem.
Weitere Grenzen: Texte, die nachträglich überarbeitet oder mit menschlichen Passagen gemischt wurden, sind für Scanner besonders schwer einzuordnen. Und einfache Paraphrasierungstools können die Erkennung in vielen Fällen komplett aushebeln.
Was das für Unternehmen bedeutet
Wer KI im Unternehmen einsetzt, muss verstehen, was KI-Scanner leisten und was nicht.
Eigener Content
Wenn ein Unternehmen KI-gestützt Texte erstellt, sei es für Blog, Newsletter oder Social Media, stellt sich die Frage: Erkennt Google das? Die kurze Antwort: Google bewertet Inhalte nach Qualität und Nutzwert, nicht nach Herkunft. Das sehen wir auch in unserer Arbeit als GEO Agentur. Wer KI-Texte ohne redaktionelle Überarbeitung veröffentlicht, riskiert gleichförmigen Content, der weder für Leser noch für Suchmaschinen überzeugend ist.
Eingehende Texte prüfen
Manche Unternehmen setzen KI-Scanner ein, um Bewerbungen, Gastbeiträge oder Agenturleistungen zu prüfen. Das ist verständlich, aber die Fehlerquoten machen das Ergebnis zu einer Schätzung, nicht zu einem Beweis. Wer darauf basierend Bewerbungen aussortiert, trifft mit hoher Wahrscheinlichkeit Fehlentscheidungen.
Qualitätssicherung statt Detektivarbeit
Der bessere Ansatz: Nicht fragen, ob ein Text von KI stammt, sondern ob er gut ist. Ein gut überarbeiteter KI-Text kann besser sein als ein schlecht recherchierter menschlicher Text. Entscheidend ist die redaktionelle Qualität, nicht die Herkunft.
KI-Scanner sind ein Werkzeug mit begrenzter Aussagekraft. Wer sie als Richter einsetzt, überschätzt ihre Fähigkeiten. Sie können als Orientierung aber definitiv helfen.
Zusammenfassung: KI-Scanner
KI-Scanner sind technisch faszinierend, aber in der Praxis davon entfernt, zuverlässig zwischen menschlichem und KI-generiertem Text zu unterscheiden. Besonders für deutsche Texte bleiben die Ergebnisse unzuverlässig.
Für Unternehmen, die selbst KI einsetzen, ist die Frage ohnehin eine andere: Nicht ob ein Text als KI erkannt wird, sondern ob er gut genug ist, um veröffentlicht zu werden. Redaktionelle Qualität, eigene Perspektive und echte Substanz, das sind die Merkmale, die weder ein Scanner noch ein Algorithmus ersetzen können.