Prompt Engineering ist tot — das war einer der meistgeteilten Sätze der letzten Monate. Die Idee dahinter: Modelle wie ChatGPT oder Claude werden so gut, dass man ihnen einfach sagen kann, was man will. Die Realität sieht anders aus. Wer täglich mit KI arbeitet, weiß, dass die Qualität des Outputs direkt daran hängt, wie die Aufgabe gestellt wird. Was sich verändert hat, ist nicht die Relevanz des Promptings, sondern welche Techniken wirklich bessere KI-Ergebnisse liefern.
Warum ChatGPT und Co. so oft schlechte Antworten liefern
Das Modell ist selten das Problem. Häufiger liegt es daran, wie die Anfrage formuliert ist. Zu kurz, zu vage, kein Ziel, kein Format und das Modell macht, was es in diesem Fall immer tut: Es interpretiert. Und diese Interpretation stimmt selten mit dem überein, was man eigentlich wollte.
Ein hilfreicher Gedanke aus der Praxis: KI wie einen extrem talentierten, aber völlig uninformierten neuen Kollegen behandeln am ersten Arbeitstag. Wer diesem Kollegen eine unklare Aufgabe gibt, bekommt eine unklare Antwort, egal wie gut er ist. Das gilt für ChatGPT genauso wie für Claude oder Gemini.
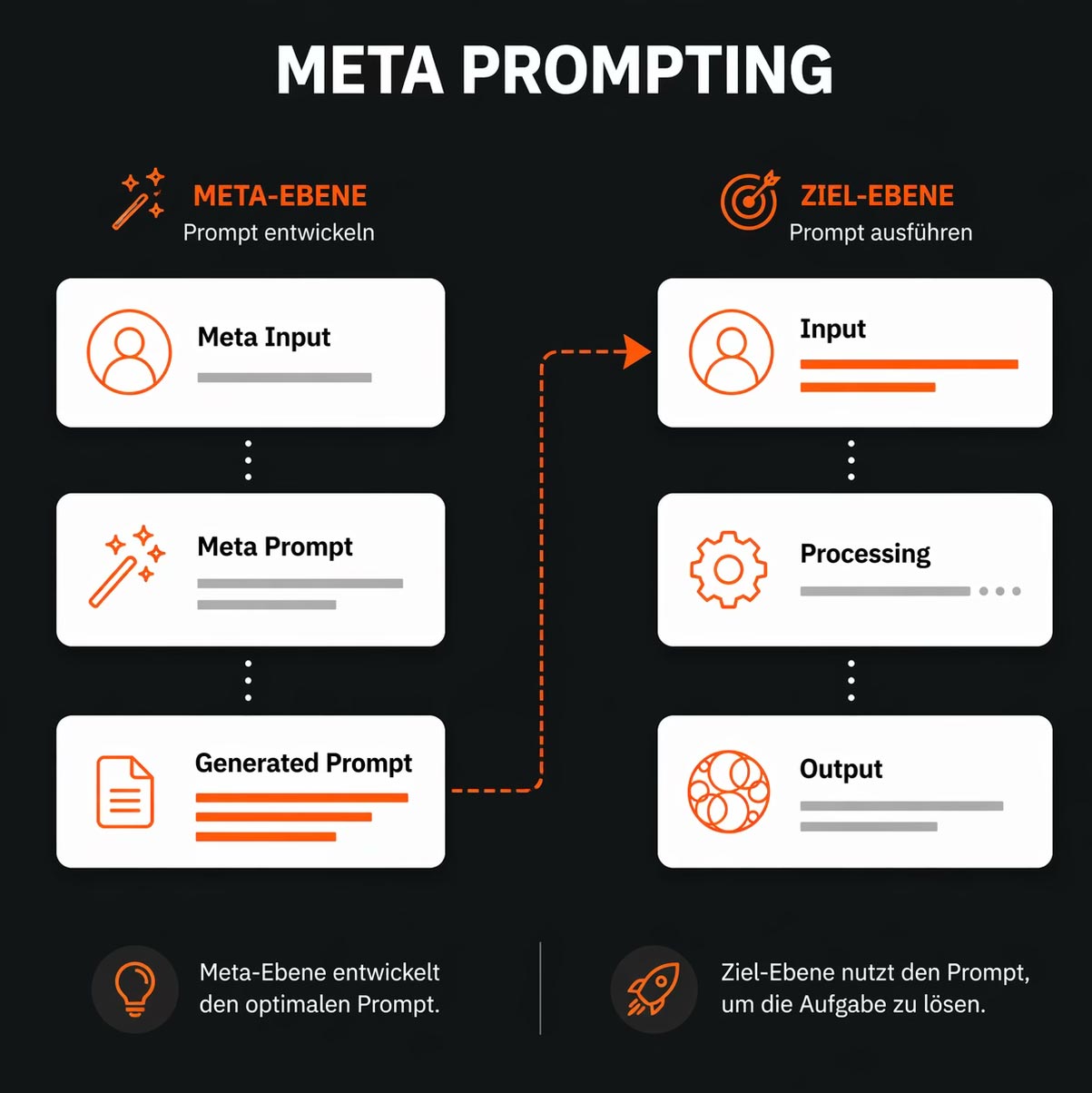
Meta-Prompting: KI verbessert den Prompt selbst
Meta-Prompting bedeutet: Die KI wird genutzt, um bessere Prompts zu schreiben, nicht um die eigentliche Aufgabe direkt zu lösen. Statt selbst lange an einem ChatGPT-Prompt zu feilen, beschreibt man das Ziel grob und lässt das Modell einen strukturierten, optimierten Prompt daraus bauen.
Eine bewährte Vorlage: "Schreib mir einen Prompt für X. Stelle mir vorher Fragen, um den Prompt zu optimieren." Das Modell stellt gezielte Rückfragen zu Ziel, Kontext,Tonalität und Format — und baut daraus einen Prompt, der präziser ist als das, was die meisten Menschen in fünf Minuten selbst formulieren würden.
Gerade für wiederkehrende Aufgaben ist Meta-Prompting ein erheblicher Zeitgewinn.
Chain of Thought Prompting
LLMs liefern bessere Ergebnisse, wenn sie gezwungen werden, laut zu denken bevor sie antworten. Der klassische Trigger ist denkbar einfach: "Denk Schritt für Schritt."
Das klingt banal, ist aber empirisch belegt. Anthropic und Google haben in mehreren Papers gemessen, dass die Fehlerrate bei komplexen Aufgaben mit dieser Aufforderung messbar sinkt. Ohne sie springt das Modell direkt zur Antwort. Mit Chain of Thought durchläuft es Zwischenschritte, prüft Annahmen und korrigiert sich selbst.
Bei neueren Modellen passiert ein Teil davon automatisch im Hintergrund durch sogenanntes Extended Thinking. Für komplexe Analysen und mehrstufige Planungsaufgaben lohnt es sich aber weiterhin, es explizit anzufordern.

ZFHK-Prompting-Framework
Das ZFHK-Framework ist die solideste Grundlage für Prompts, die konsistent bessere KI-Ergebnisse liefern. Vier Bausteine, die zusammen nahezu jede Anfrage deutlich präziser machen:

Ziel:
Was soll die Antwort konkret erreichen? Nicht "Schreib einen Text über das Produkt", sondern: "Formuliere drei Varianten für eine Instagram-Caption, die zum Kauf animiert."
Format:
Soll die Ausgabe eine Tabelle sein? Fließtext? Eine E-Mail? JSON? Ohne Formatangabe entscheidet das Modell selbst und trifft nicht immer die richtige Wahl.
Hinweise:
Was muss die KI beachten? Tonalität, Einschränkungen, Dinge, die nicht im Output auftauchen sollen.
Kontext:
Welche Hintergrundinformationen helfen bei der Bearbeitung? Produktbeschreibung, Zielgruppe, Unternehmenskontext.
Das Framework geht auf Greg Brockmann, Mitgründer von OpenAI, zurück. Es zwingt dazu, vor dem Schreiben zu denken und genau das verändert die Qualität des Outputs spürbar. Wer die Grundlagen des Promptings bereits kennt, kann mit den folgenden drei Techniken direkt aufsetzen.
Multishot-Prompting — Beispiele statt Erklären
Multishot-Prompting ist einer der am meisten unterschätzten Hebel für bessere KI-Ergebnisse. Die Idee ist simpel:Statt der KI zu erklären, wie ein Text klingen soll, zeigt man ihr Beispiele.
Der Unterschied zur Erklärung ist enorm. "Schreib sachlich und nahbar" interpretiert jedes Modell anders. Wer stattdessen zwei Texte zeigt, die sachlich und nahbar sind, lässt kaum Interpretationsspielraum. Das Modell erkennt Tonalität, Länge und Struktur und repliziert das Muster zuverlässig.
Die Faustregel: zwei bis fünfBeispiele. Mehr ist häufig kontraproduktiv, weil das Kontextfenster belastet wird und das Modell beginnt, die Beispiele zu overfitten statt das Muster zu abstrahieren.
Wann System-Prompts wichtiger sind als der einzelne Prompt
Ein Aspekt, der im Alltag oft übersehen wird: die Unterscheidung zwischen System-Prompt und User-Prompt. Der System-Prompt ist die dauerhafte Grundkonfiguration. Einmal gesetzt, gilt er für die gesamte Session oder den gesamten Workflow. Er definiert Rolle, Tonalität und Verhalten. Der User-Prompt ist die situative Eingabe, die sich bei jedem Durchlauf ändert.
Je sauberer der System-Prompt geschrieben ist, desto weniger muss im User-Prompt erklärt werden. Und weil der System-Prompt bei jedem Durchlauf aktiv ist, skaliert jeder Fehler darin auf jede einzelne Interaktion. Wer regelmäßig mit KI-Workflows arbeitet, sollte dort ansetzen, nicht bei der Optimierung einzelner Prompts. Mehr dazu, wie sich das in der Praxis mit wiederverwendbaren Skills verbinden lässt, haben wir separat beschrieben.
Fazit: So verbessert man KI-Prompts wirklich
Prompting bleibt relevant aber der Fokus verschiebt sich. Wer KI-Prompts verbessern will oder generell bessere KI-Ergebnisse braucht, kommt mit diesen vier Techniken am weitesten: ZFHK für Struktur, Multishot für Stil und Tonalität, Chain of Thought für komplexe Aufgaben, Meta-Prompting für Effizienz.
Der sinnvollste Einstieg: Eine Aufgabe identifizieren, die regelmäßig unbefriedigende Ergebnisse liefert, und sie einmal mit einer dieser vier Techniken neu formulieren. Der Unterschied ist meistens sofort sichtbar.